Ola!! Depois de algum tempo sem publicar, estou colocando um novo post.
Encontrei um hint muito interessante, que fornece uma abordagem alternativa ao inserir dados onde valores duplicados podem vir a ser um problema.
Nas versões mais antigas do Oracle, eram usados em uma rotina PL/SQL, além de manipuladores de exceção ou instruções SQL que impediam a duplicação.
Como o Oracle 10g, o problema podia ser combatido com uma instrução MERGE,
embora o MERGE existisse desde a versão 9i, ele ainda precisava lidar com WHEN MATCHED e WHEN NOT MATCHED, o que em muitas aplicações isso não é viável.
O Oracle na versão 11.2.0.1 possui um recurso que permite silenciosamente inserir SQL para aceitar linhas duplicadas com o hint ignore_row_on_dupkey_index .
Quando hint ignore_row_on_dupkey_index é usado em uma instrução insert numa tabela com um índice de chave exclusivo, quaisquer linhas duplicadas serão silenciosamente ignoradas, em vez de causar o tradicional erro, ORA-00001 unique constraint violated .
Abaixo farei um cenário para testes, onde mostraremos o uso de hint ignore_row_on_dupkey_index :
I – USO DO HINT
Neste Cenário de testes, usarei uma tabela com 15 linhas com um índice de chave exclusiva, aonde tentarei inserir novas linhas a fim de ilustrar o uso do hint.
1 – Criando uma tabela de testes
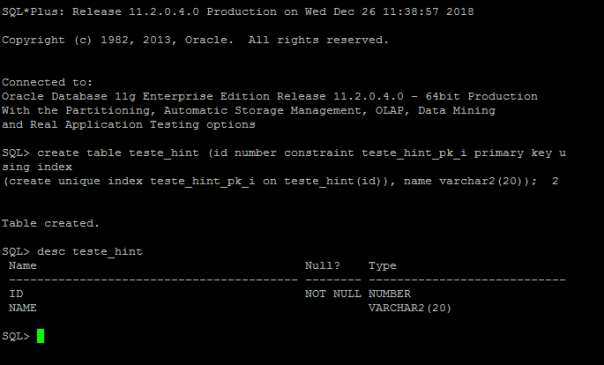
2 – Verificar índice único criado

3 – Adicionar linhas a tabela
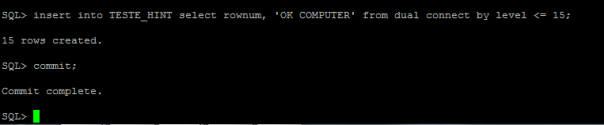
4 – Verificar as linhas adicionadas na tabela
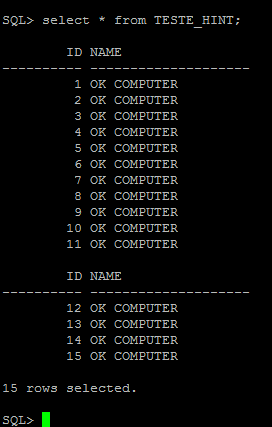
5 – Adicionar linhas com valores duplicados
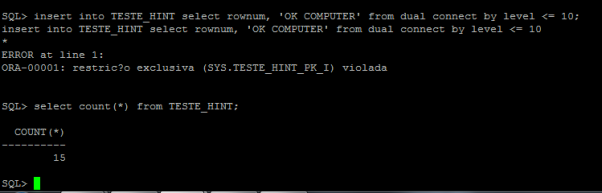
Obs: Obviamente recebemos um erro de violação de restrição exclusiva e não ocorreu inserção na tabela.
Neste momento usarei o hint IGNORE_ROW_ON_DUPKEY_INDEX para adicionar linhas a tabela de testes, mesmo com registros duplicados. Assim poderemos verificar que o uso do hint IGNORE_ROW_ON_DUPKEY_INDEX , lidará silenciosamente com os erros de violação exclusivas de restrição, simplesmente ignorando e não inserindo nenhuma linha na qual os valores exclusivos já existam na tabela.
6 – Inserindo linha usando hint IGNORE_ROW_ON_DUPKEY_INDEX
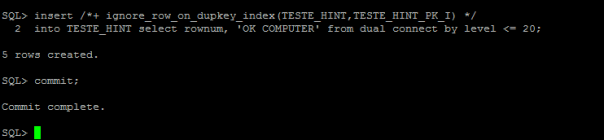
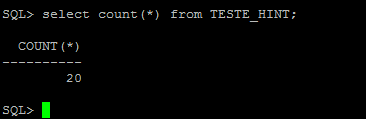
Observe que os 15 valores duplicados (1 – 15) foram ignorados e não foram inseridos na tabela, mas os valores 16 a 20 que não existiam anteriormente foram inseridos com êxito na tabela.
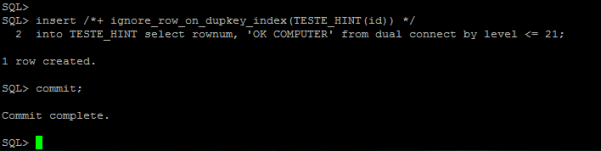
No próximo exemplo, tentaremos inserir os valores de 1 a 21 na tabela, embora atualmente os valores entre 1 a 20 já existam. Desta vez, usaremos um segundo formato da usando o hint que nos permite estipular a coluna que contém valores exclusivos que devem ser ignorados se já existirem:
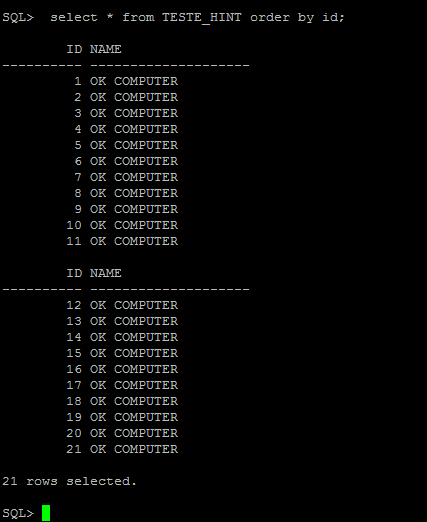
Note que na figura abaixo, os valores entre 1 e 20 foram silenciosamente ignorados com apenas o valor 21 inserido desta vez na tabela.
II – RESTRIÇÕES
O hint IGNORE_ROW_ON_DUPKEY_INDEX não pode ser usado dentro de uma instrução UPDATE.
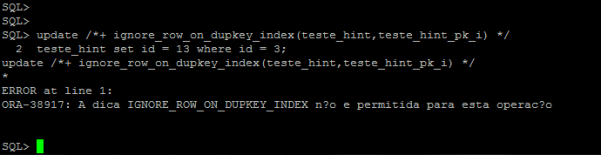
OBS: Uma diferença interessante no comportamento deste hint. Geralmente, os hints “inválidos” são apenas ignorados e tratados como comentários, mas para este hint, se uma operação ilegal for tentada, um erro ocorre.
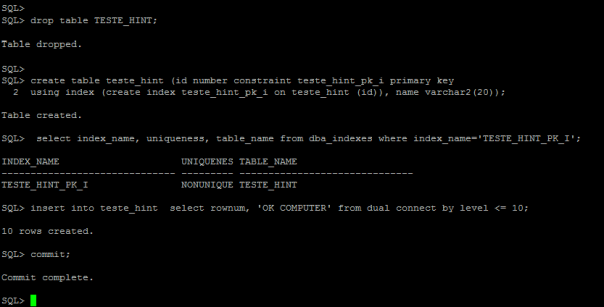
Abaixo repetiremos os testes, mas dessa vez criaremos uma tabela sem chave primária por meio de um índice não-exclusivo.
Observe novamente que um erro será invocado aqui, bem como verificaremos que esse hint só pode ser aplicado por meio de uma restrição policiada por um índice exclusivo. Um índice não exclusivo, mesmo com uma restrição Unique ou PK em vigor, não é suficiente e gerará o erro abaixo:
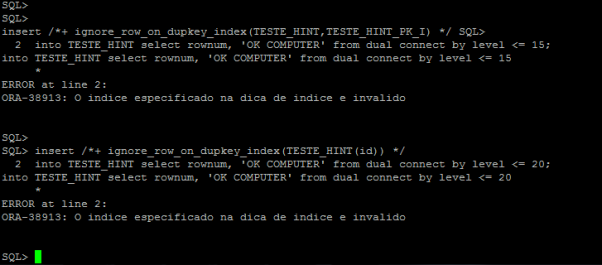
Atualmente, apesar da conveniência associada ao uso do hint IGNORE_ROW_ON_DUPKEY_INDEX, há também outras limitações. Portanto, o índice fornecido no hint deve existir. Caso contrário o hint não é ignorada como de costume, mas um erro ocorrerá. Além disso, os INSERTs que usam a este hint não podem se beneficiar de Paralelismo, Direct Path ou NOLOGGING.
CONCLUSÃO
É claramente muito mais eficiente evitar inserir linhas duplicadas do que inseri-las e manipular a exceção ou usar o hint IGNORE_ROW_ON_DUPKEY_INDEX. Portanto, ainda é muito mais eficiente evitar inserir linhas duplicadas em primeiro lugar. Caso isso não seja possível, use o hint IGNORE_ROW_ON_DUPKEY_INDEX, mas leve em consideração as restrições acima citadas.
