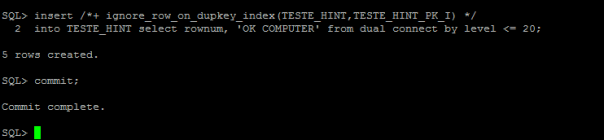
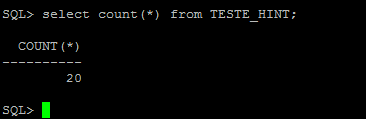
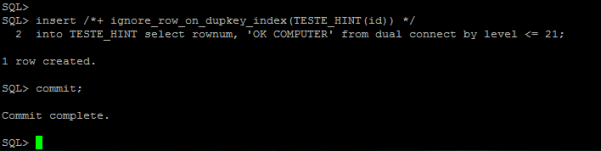
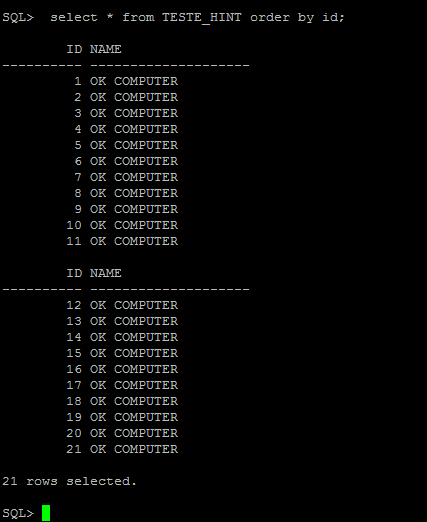
Esse post mostra um conceito básico de tabelas externas. Uma External Table é uma funcionalidade presente em uma serie de SGBDs, cada um com o seu nome e sintaxe próprias. As tabelas externas, estão disponíveis desde a versão Oracle9i. Uma tabela externa nada mais é do que uma tabela criada no banco de dados, cuja sua origem de dados está vinculada a um arquivo de texto, eliminando imediatamente a necessidade de carregar arquivos de texto em tabelas intermediárias visando economia no processamento de tempo e em espaço de armazenamento.
As tabelas externas são muito utilizadas em ambientes de data warehouse, extração, transformação e carregamento (ETL), no qual, esses processos podem ler o arquivo de texto de uma tabela externa direta e posteriormente carregar os dados em tabelas de resumo. Conforme dito acima, os processos ETL elimina a etapa de carregar os arquivos de texto em armazenamento intermediário, economizando espaço e tempo significativo, ou seja , isto é feito atraves da utilizaçao de arquivos “FLAT FILES” e Tabelas Relacionais sem a necessidade de uma ferramenta específica de ETL.
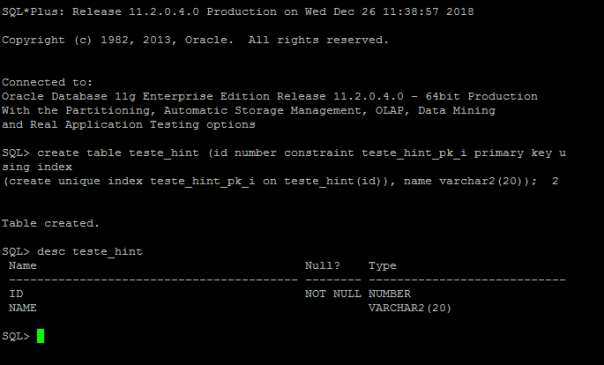
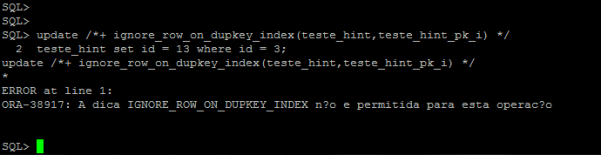
Quando criamos uma tabela simples no banco de dados Oracle podemos utilizar as instruções DML (ex. INSERT, UPDATE, DELETE) para manipular as informações. Uma conseqüência disso é que você não pode criar um índice em uma tabela externa.
Abaixo veremos como criar tabela externas em ambiente de banco de dados Oracle.Para esse teste o ambiente utilizado é linux com banco de dados Oracle 11g R2.
1 – Criar um diretório no sistema operacional
Como os dados de uma tabela externa está no sistema operacional, o arquivo de dados precisa estar em um lugar aonde o Oracle pode acessá-lo. Então o primeiro passo é criar um diretório e conceder acesso a ele. Primeiro, crie o diretório no sistema operacional ou escolha um diretório existente. Ele deve ser um diretório real, não um link simbólico. Certifique se o acesso de leitura e escrita do usuário oracle estão com as devidas permissões neste diretório.
No sistema operacional foi criado uma pasta chamada post no diretório /home/oracle.
[oracle@localhost]$ mkdir -p /home/oracle/post
[oracle@ localhost ]$ ls -l *
total 17520
-rw-rw-r– 1 oracle oracle 68 Jul 25 18:09 afiedt.buf
drwxr-xr-x 4 oracle oracle 4096 Jun 1 2013 ap
drwxrwxr-x 5 oracle oracle 4096 Jun 12 14:05 backup
drwxrwxr-x 3 oracle oracle 4096 Dez 5 2011 oradiag_oracle
drwxrwxr-x 2 oracle oracle 4096 Jul 27 14:57 post
drwxrwxr-x 2 oracle oracle 4096 Jun 12 14:38 scripts
-rw-rw-r– 1 oracle oracle 1750 Dez 7 2013 Untitled.sql
2 – Criar um diretório no banco de dados Oracle
As tabelas externas usam diretórios do Oracle. Um diretório Oracle é uma referência interna no dicionário de dados. Um diretório mapeia um nome de diretório exclusivo para um diretório físico no sistema operacional local.
Para criar um diretório no banco de dados, é necessário ter acesso SYSDBA. O “diretório” será uma pasta mapeada em seu servidor, onde, haverá uma vinculo direto com o banco de dados e será possível determinar privilégios de acesso a determinados usuários/schemas. Antes de criar um diretório de banco de dados, é necessário criar uma pasta fisicamente no servidor. Conforme citado acima o diretório sera criado em ‘/home/oracle/post’.
SQL> create directory external as ‘/home/oracle/post’;
Directory created.
SQL> grant read, write on directory external to hr;
Grant succeeded.
3 – Criando uma tabela externa
A última etapa de preparação para criação de uma tabela externa exige que um arquivo de texto simples seja criado no diretório físico criado no S.O. e no banco de dados respectivamente.
3.1 – Criando um arquivo texto
No diretório ‘/home/oracle/post’ foi criado um arquivo texto chamado empregado.csv. Segue abaixo o conteudo deste arquivo que usaremos para testes.
[oracle@localhost post]$ cat empregado.csv
001,Hutt,Jabba,jabba@thecompany.com
002,Simpson,Homer,homer@thecompany.co
03,Kent,Clark,superman@thecompany.com
004,Kid,Billy,billythkid@thecompany.com
005,Stranger,Perfect,nobody@thecompany.com
006,Zoidberg,Dr,crustacean@thecompany.com
007,Lane,Lois,loislane@thecompany.com
008,Bane,David,hulk@thecompany.com
009,Stark,Tony,ironman@thecompany.com
010,House,Gregory,drhouse@thecompany.com
011,Wayne,Bruce,batman@thecompany.com
012,Park,Peter,spiderman@thecompany.com
[oracle@localhost post]$
3.2 – Criando uma tabela externa
A sintaxe para criação de uma tabela externa é muito parecida com a sintaxe de criação de uma tabela normal. A primeira parte é como um CREATE TABLE normal, tem o nome da tabela e das colunas. Depois é seguido por um bloco de sintaxe específica para tabelas externas, o que permite que você informe o Oracle como interpretar os dados no arquivo externo.
A cláusula DEFAULT DIRECTORY, especifica o diretório padrão a ser usado para todos os arquivos de entrada e saída.
A cláusula LOCATION, lista todos os arquivos de dados para a tabela externa.
A cláusula ACCESS PARAMETERS é onde os arquivos de saída são nomeados.
SQL> connect hr/hr
Connected.
SQL> create table empregados
2 ( emp_id varchar2(3),
3 last_name varchar2(50),
4 first_name varchar2(50),
5 email varchar2(100)
6 )
7 organization external
8 ( default directory external
9 access parameters
10 ( records delimited by newline
11 fields terminated by ‘,’
12 )
13 location (‘empregado.csv’)
14 );
Table created.
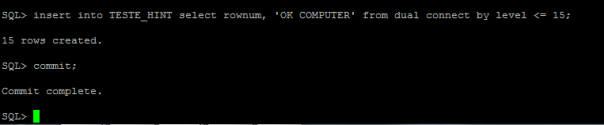
Apos criada a tabela, vamos conferir os dados criados:
SQL> select count(*) from empregados;
COUNT(*)
———-
12
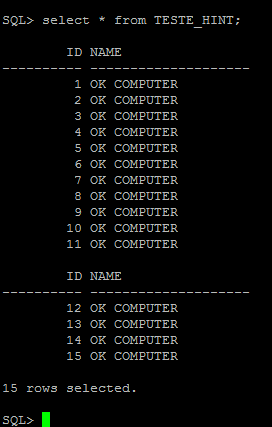
SQL> select * from empregados;
EMP LAST_NAME FIRST_NAME EMAIL
— ———- ———- ——————————
001 Hutt Jabba jabba@thecompany.com
002 Simpson Homer homer@thecompany.com
003 Kent Clark superman@thecompany.com
004 Kid Billy billythkid@thecompany.com
005 Stranger Perfect nobody@thecompany.com
006 Zoidberg Dr crustacean@thecompany.com
007 Lane Lois loislane@thecompany.com
008 Bane David hulk@thecompany.com
009 Stark Tony ironman@thecompany.com
010 House Gregory drhouse@thecompany.com
011 Wayne Bruce batman@thecompany.com
012 Parker Peter spiderman@thecompany.com
12 rows selected.
SQL>
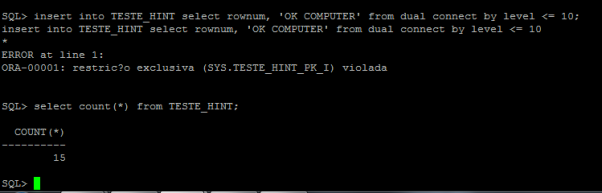
Conforme falamos acima, uma tabela externa não aceita comandos DML, ela deve ser feita somente no arquivo texto. Caso tente realizar essas alterações utilizando DMLs, o resultado será:
SQL> insert into empregados values
2 (‘013′,’Steven’,’Rogers’,’capitaoamerica@thecompany.com’)
SQL> /
insert into empregados values
*
ERROR at line 1:
ORA-30657: operation not supported on external organized table
como vimos acima, a operação apresentou o erro ORACLE ORA-30657.
3.3 – Alterando uma tabela externa
Você pode usar o commando ALTER TABLE para alterar os parâmetros de acesso sem dropa-la e redefinir a tabela inteira:
SQL> alter table empregados
2 access parameters
3 ( records delimited by newline
4 badfile ‘empregado.bad’
5 logfile ‘empregado.log’
6 discardfile ‘empregado.dsc’
7 fields terminated by ‘,’
8 )
SQL> /
Table altered.
SQL>
3.4 – Visualizando o dicionários de dados
Os metadados são armazenadas em duas visões, chamadas USER_EXTERNAL_TABLES e USER_EXTERNAL_LOCATIONS (que, naturalmente, podem ser vistas nas visões ALL_ ou DBA_). O diretório virtual é armazenada na visão USER_EXTERNAL_TABLES, enquanto o nome do arquivo físico é armazenado na exibição USER_EXTERNAL_LOCATIONS.
3.4.1 – Consultando a visão USER_EXTERNAL_LOCATIONS
SQL> select * from user_external_locations where table_name = ‘EMPREGADOS’;
TABLE_NAME LOCATION DIR DIRECTORY_NAME
———— ——————– — ——————————
EMPREGADOS empregado.csv SYS EXTERNAL
3.4.2 – Consultando a visão USER_EXTERNAL_TABLES
SQL>select * from user_external_tables where table_name = ‘EMPREGADOS’;
TABLE_NAME TYP TYPE_NAME DEF DEFAULT_DIRECTORY_NAME REJECT_LIMIT ACCESS_
———— — ————— — —————————— ————- ——-
ACCESS_PARAMETERS PROPERTY
——————————————————————————– ———-
EMPREGADOS SYS ORACLE_LOADER SYS EXTERNAL 0 CLOB
records delimited by newline ALL
badfile ‘empregado.bad’
4 – Criando tabela externa apartir de tabela do banco de dados
O Oracle permite criar uma nova tabela externa a partir de dados em outras tabelas em seu banco de dados, que entra por um FLAT FILE usando o driver de acesso ORACLE_DATAPUMP. Este FLAT FILE está em um formato proprietário da Oracle que pode ser lido por DataPump. A sintaxe é semelhante a sintaxe CREATE TABLE … ORGANIZATION EXTERNAL acima, porém mais simples, uma vez que não é possível especificar o formato de dados, você pode especificar alguns parametros de acesso. A principal diferença é que você deve especificar o driver de acesso, ORACLE_DATAPUMP, desde que o driver de acesso predefinido para ORACLE_LOADER.
Vamos aos testes:
SQL> create table export_teste
2 organization external
3 ( type oracle_datapump
4 default directory external
5 location (‘teste.dmp’)
6 ) as select * from employees;
Table created.
SQL>
Depois de criada a tabela vamos verificar os dados:
SQL> select count(*) from export_teste;
COUNT(*)
———-
107
SQL> select * from export_teste where rownum < 5;
EMPLOYEE_ID FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID SALARY
———– ———- ———- ———— ———— ——— ———- ———-
COMMISSION_PCT MANAGER_ID DEPARTMENT_ID
————– ———- ————-
198 Donald OConnell DOCONNEL 650.507.9833 21-JUN-07 SH_CLERK 2600 124 50
199 Douglas Grant DGRANT 650.507.9844 13-JAN-08 SH_CLERK 2600 124 50
200 Jennifer Whalen JWHALEN 515.123.4444 17-SEP-03 AD_ASST 4400 101 10
201 Michael Hartstein MHARTSTE 515.123.5555 17-FEB-04 MK_MAN 13000 100 20
CONCLUSÃO
Nós vimos acima uma introdução de carga de dados usando tabelas externas. As tabelas externas fornecem uma maneira conveniente de mover dados para dentro e fora do banco de dados, com integração do SQLLoader, agregando funcionalidade do Data Pump e a facilidade no uso de instruções SQL. Definitivamente vale a pena considerar o uso de tabelas externas na tarefa de carregar dados ao banco. Segue abaixo o link da documentação da ORACLE para melhor compreensão do assunto.
LINK LINK2